
L’allongement des consonnes marque le début des mots
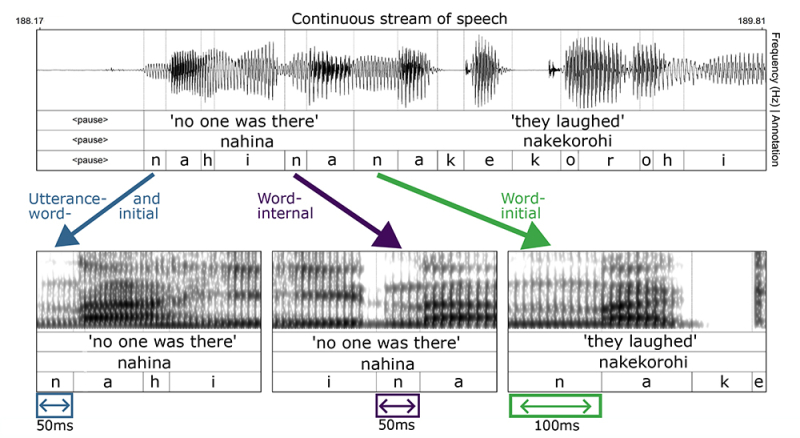
La parole consiste à émettre un flux continu de signaux acoustiques ; pourtant, les humains sont capables de segmenter les mots avec une précision et une rapidité étonnante. Pour comprendre cette capacité, une équipe internationale de linguistes a analysé, dans le discours oral, la durée des consonnes placées à différentes positions dans les mots et ce, pour un échantillon varié de langues. Ils ont découvert que les consonnes initiales sont en moyenne 13 millisecondes plus longues que les consonnes occupant une autre position dans les mots. Étant donné la diversité des langues dans lesquelles cette observation est faite, il semblerait que ce schéma concerne toutes les langues humaines. C’est aussi sans doute l’un des facteurs clés, dans la perception de la parole, permettant de distinguer le début des mots dans un flux de parole.
L’une des choses les plus difficiles dans la compréhension de la langue orale, c’est de distinguer les mots les uns des autres. Pourtant, c’est une tâche que les humains font naturellement, même dans les langues dans lesquelles le début et la fin des mots ne semblent pas nettement marqués. Quels sont les indices acoustiques qui les aident à réaliser ce processus ? Une question restée jusqu’ici sans réponse pour la grande majorité des langues, faute d’études suffisantes sur le sujet. Mais les choses évoluent. Pour la première fois, des linguistes comparatifs ont observé un schéma d’effets acoustiques qui pourrait servir de séparation claire dans diverses langues : l’allongement systématique des consonnes initiales.
Les chercheurs du laboratoire Structure et dynamique des langues (SeDyL, UMR8202, CNRS, Inalco, IRD), du Max Planck Institute for Evolutionary Anthropology (MPI-EVA), de l'université Humboldt de Berlin et du Leibniz-Centre General Linguistics (ZAS) ont utilisé les données du nouveau [corpus DoReCo], qui répond à deux critères. Premièrement, il couvre un volume de discours oral d’une diversité linguistique et culturelle sans précédent, composé d’échantillons de 51 populations de tous les continents habités. Deuxièmement, il fournit des informations précises sur la durée de chaque son prononcé du corpus, qui en comporte plus d’un million. « En raison de l’immense diversité inter-linguistique, il est essentiel que DoReCo offre une couverture mondiale afin de mettre au jour des schémas communs à toutes les langues humaines », explique Frank Seifart, auteur principal, chargé de recherche CNRS au SeDyL (Paris) et à l'université Humboldt de Berlin, et coéditeur de DoReCo.
L’allongement des consonnes initiales : un élément universel ?
« Au début, nous nous attendions à trouver des preuves contraires à l’hypothèse selon laquelle l’allongement des consonnes initiales est une caractéristique linguistique universelle. Nous avons été très surpris en découvrant les résultats de notre analyse », raconte Frederic Blum, premier auteur et doctorant au MPI-EVA, qui a lancé et dirigé l’étude. « Les résultats suggèrent en effet que ce phénomène serait commun à la plupart des langues ». Dans 43 des 51 langues de l’échantillon, l’étude fait clairement ressortir cet effet d’allongement. Dans les huit autres langues, en revanche, les résultats n’ont pas permis de tirer de conclusion.
Les auteurs concluent que l’allongement pourrait être l’un des facteurs qui aident les interlocuteurs d’une conversation à identifier les séparations entre les mots, et ainsi à segmenter le discours en mots distincts. Un autre de ces facteurs pourrait être l’effort d’articulation, sujet qui n’a pas encore fait l’objet d’études comparatives approfondies. Par ailleurs, dans l’étude actuelle, certaines langues montraient également des signes de raccourcissement en début d’énoncé, lorsque celui-ci intervenait après une pause. Cette observation est cohérente avec la conclusion des auteurs ; en effet, si le locuteur marque une pause, aucun autre indice n’est nécessaire pour marquer la séparation entre les mots.
Cette étude permet de mieux comprendre les processus acoustiques communs à toutes les langues parlées. En s’intéressant plus particulièrement aux langues des populations non « WEIRD1 » (occidentales, éduquées, industrialisées, riches, démocratiques), les chercheurs espèrent élargir nos connaissances des processus cognitifs liés à la parole et communs à toutes les populations.
Référence :
Blum F., Paschen L., Forkel R., Fuchs S., Seifart F. 2024, Consonant lengthening marks the beginning of words across a diverse sample of languages, Nature Human Behaviour.
Laboratoire
Structure et dynamique des langues (SeDyL - CNRS/Inalco/IRD)